Machine Learning A-Z: Part 3 – Classification (Logistic Regression)
Linear Regression
– Simple:
y = b0 + b1 * x1
– Multiple:
y = b0 + b1 * x1 + … + bn * xn
Logistic Regression
Sigmoid Function:
p = 1 / (1 + e-y)
ln * (p / (1 – p)) = b0 + b1 * x
y: Actual DV [dependent variable]
p^: Probability [p_hat]
y^: Predicted DV
Implementation
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
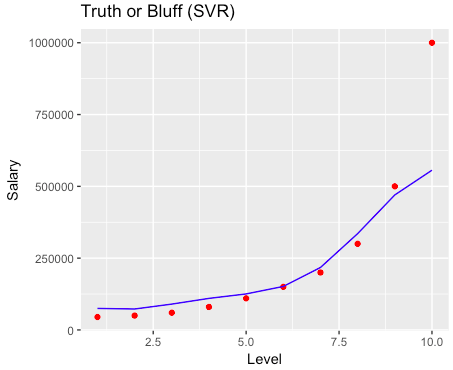
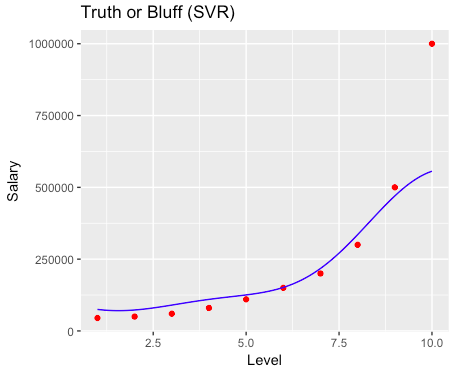
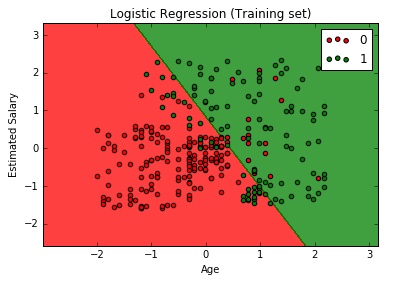
# Logistic Regression # Importing the dataset dataset = pd.read_csv('Social_Network_Ads.csv') X = dataset.iloc[:, [2,3]].values y = dataset.iloc[:, 4].values # Splitting the dataset into the Training set and Test set from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # Feature Scaling from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test) # Fitting the Regression to the dataset from sklearn.linear_model import LogisticRegression classifier = LogisticRegression(random_state = 0) classifier.fit(X_train, y_train) # Predicting a new result y_pred = classifier.predict(X_test) # Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) # Visualizing the Training set results from matplotlib.colors import ListedColormap X_set, y_set = X_train, y_train X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('red', 'green'))(i), label = j) plt.title('Logistic Regression (Training set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show() # Visualizing the Test set results from matplotlib.colors import ListedColormap X_set, y_set = X_test, y_test X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('red', 'green'))(i), label = j) plt.title('Logistic Regression (Test set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show() |
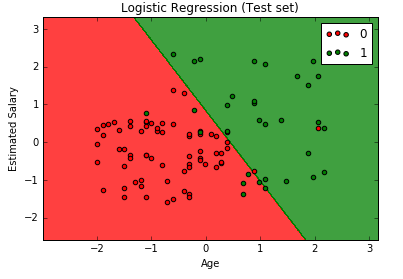
R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# Logistic Regression # Importing the dataset dataset = read.csv('Social_Network_Ads.csv') dataset = dataset[, 3:5] # Splitting the dataset into the Training set and Test set # install.packages('caTools') library(caTools) set.seed(123) split = sample.split(dataset$Purchased, SplitRatio = 0.75) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE) # Feature Scaling training_set[, 1:2] = scale(training_set[, 1:2]) test_set[, 1:2] = scale(test_set[, 1:2]) # Fitting Logistic Regression to the Training set classifier = glm(formula = Purchased ~ ., family = binomial, data = training_set) # Predicting the Test set results prob_pred = predict(classifier, type = 'response', newdata = test_set[-3]) y_pred = ifelse(prob_pred > 0.5, 1, 0) # Making the Confusion Matrix cm = table(test_set[, 3], y_pred) # Visualising the Training set results # install.packages('ElemStatLearn') library(ElemStatLearn) set = training_set X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01) X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01) grid_set = expand.grid(X1, X2) colnames(grid_set) = c('Age', 'EstimatedSalary') prob_set = predict(classifier, type = 'response', newdata = grid_set) y_grid = ifelse(prob_set > 0.5, 1, 0) plot(set[, -3], main = 'Logistic Regression (Training set)', xlab = 'Age', ylab = 'Estimated Salary', xlim = range(X1), ylim = range(X2)) contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE) points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato')) points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3')) # Visualising the Test set results # install.packages('ElemStatLearn') # library(ElemStatLearn) set = test_set X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01) X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01) grid_set = expand.grid(X1, X2) colnames(grid_set) = c('Age', 'EstimatedSalary') prob_set = predict(classifier, type = 'response', newdata = grid_set) y_grid = ifelse(prob_set > 0.5, 1, 0) plot(set[, -3], main = 'Logistic Regression (Test set)', xlab = 'Age', ylab = 'Estimated Salary', xlim = range(X1), ylim = range(X2)) contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE) points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato')) points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3')) |
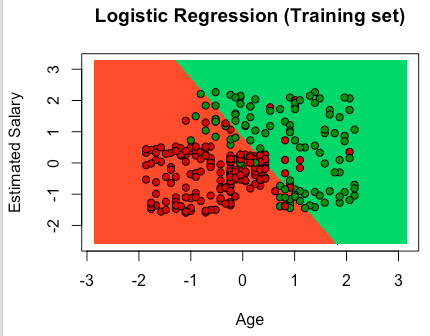
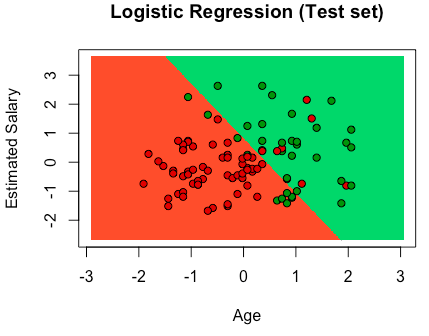
Templates
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
# Classification Template # Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd # Importing the dataset dataset = pd.read_csv('Social_Network_Ads.csv') X = dataset.iloc[:, [2,3]].values y = dataset.iloc[:, 4].values # Splitting the dataset into the Training set and Test set from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # Feature Scaling from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test) # Fitting the classifier to the dataset # Create your classifier here # Predicting a new result y_pred = classifier.predict(X_test) # Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) # Visualizing the Training set results from matplotlib.colors import ListedColormap X_set, y_set = X_train, y_train X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('red', 'green'))(i), label = j) plt.title('Logistic Regression (Training set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show() # Visualizing the Test set results from matplotlib.colors import ListedColormap X_set, y_set = X_test, y_test X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('red', 'green'))(i), label = j) plt.title('Logistic Regression (Test set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show() |
R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
# Classification Template # Importing the dataset dataset = read.csv('Social_Network_Ads.csv') dataset = dataset[3:5] # Encoding the target feature as factor dataset$Purchased = factor(dataset$Purchased, levels = c(0,1)) # Splitting the dataset into the Training set and Test set # install.packages('caTools') library(caTools) set.seed(123) split = sample.split(dataset$Purchased, SplitRatio = 0.75) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE) # Feature Scaling training_set[-3] = scale(training_set[-3]) test_set[-3] = scale(test_set[-3]) # Fitting classifier to the Training set # Create your classifier here # Predicting the Test set results prob_pred = predict(classifier, type = 'response', newdata = test_set[-3]) y_pred = ifelse(prob_pred > 0.5, 1, 0) # Making the Confusion Matrix cm = table(test_set[, 3], y_pred > 0.5) # Visualising the Training set results # install.packages('ElemStatLearn') library(ElemStatLearn) set = training_set X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01) X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01) grid_set = expand.grid(X1, X2) colnames(grid_set) = c('Age', 'EstimatedSalary') prob_set = predict(classifier, type = 'response', newdata = grid_set) y_grid = ifelse(prob_set > 0.5, 1, 0) plot(set[, -3], main = 'Classifier (Training set)', xlab = 'Age', ylab = 'Estimated Salary', xlim = range(X1), ylim = range(X2)) contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE) points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato')) points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3')) # Visualising the Test set results # install.packages('ElemStatLearn') # library(ElemStatLearn) set = test_set X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01) X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01) grid_set = expand.grid(X1, X2) colnames(grid_set) = c('Age', 'EstimatedSalary') prob_set = predict(classifier, type = 'response', newdata = grid_set) y_grid = ifelse(prob_set > 0.5, 1, 0) plot(set[, -3], main = 'Classifier (Test set)', xlab = 'Age', ylab = 'Estimated Salary', xlim = range(X1), ylim = range(X2)) contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE) points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato')) points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3')) |