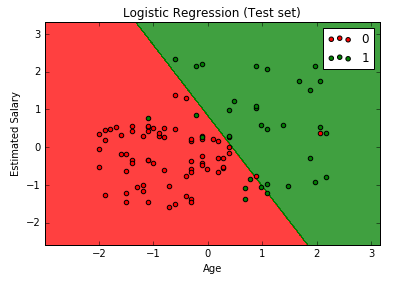
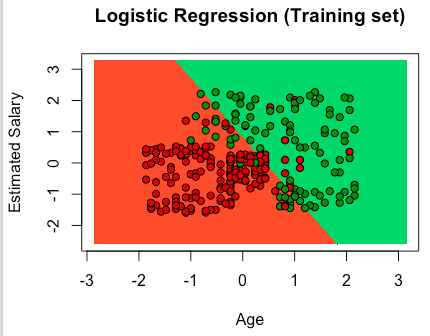
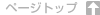Machine Learning A-Z: Part 2 – Regression (Polynomial Regression)
Polynomial Regression
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
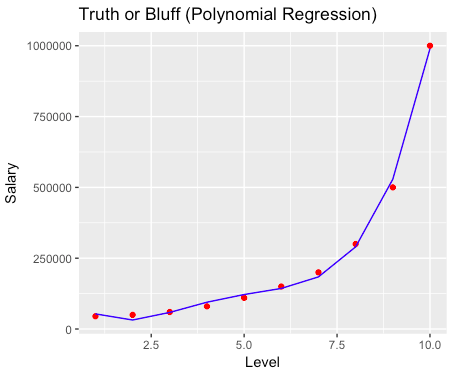
# Polynomial Regression # Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd # Importing the dataset dataset = pd.read_csv('Position_Salaries.csv') X = dataset.iloc[:, 1:2].values y = dataset.iloc[:, 2].values # Splitting the dataset into the Training set and Test set """from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)""" # Feature Scaling """from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test) sc_y = StandardScaler() y_train = sc_y.fit_transform(y_train)""" # Fitting Linear Regression to the dataset from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X, y) # Fitting Polynomial Regression to the dataset from sklearn.preprocessing import PolynomialFeatures poly_reg = PolynomialFeatures(degree = 4) X_poly = poly_reg.fit_transform(X) poly_reg.fit(X_poly, y) lin_reg_2 = LinearRegression() lin_reg_2.fit(X_poly, y) # Visulalizing the Linear Regression results plt.scatter(X, y, color = 'red') plt.plot(X, lin_reg.predict(X), color = 'blue') plt.title('Truth or Bluff (Linear Regression)') plt.xlabel('Position level') plt.show() # Visualizing the Polynomial Regression results plt.scatter(X, y, color = 'red') # lineal regression # plt.plot(X, lin_reg.predict(X), color = 'blue') # simple polynomial # plt.plot(X, lin_reg_2.predict(poly_reg.fit_transform(X)), color = 'blue') # more accurate polynomial X_grid = np.arange(min(X), max(X), 0.1) X_grid = X_grid.reshape((len(X_grid), 1)) plt.plot(X_grid, lin_reg_2.predict(poly_reg.fit_transform(X_grid)), color = 'blue') plt.title('Truth or Bluff (Polynomial Regression)') plt.xlabel('Position level') plt.ylabel('Salary') plt.show() # Predicting a new result with Linear Regression lin_reg.predict(6.5) # Predicting a new result with Polynomial Regression lin_reg_2.predict(poly_reg.fit_transform(6.5)) |
Reset console.
|
1 2 3 4 |
from IPython import get_ipython get_ipython().magic('reset -sf') def __reset__(): get_ipython().magic('reset -sf') |
IPythonコンソール|カーネルの再起動
Show summary.
|
1 |
summary(poly_reg) |
R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# Polynomial Regression # Importing the dataset dataset = read.csv('Position_Salaries.csv') dataset = dataset[2:3] # Splitting the dataset into the Training set and Test set # install.packages('caTools') # library(caTools) # set.seed(123) # split = sample.split(dataset$DependentVariable, SplitRatio = 0.8) # training_set = subset(dataset, split == TRUE) # test_set = subset(dataset, split == FALSE) # Feature Scaling # training_set = scale(training_set) # test_set = scale(test_set) # Fitting Linear Regression to the dataset lin_reg = lm(formula = Salary ~ ., data = dataset) # Fitting Polynomial Regression to the dataset dataset$Level2 = dataset$Level^2 dataset$Level3 = dataset$Level^3 dataset$Level4 = dataset$Level^4 poly_reg = lm(formula = Salary ~ ., data = dataset) # Visualising the Linear Regression results # install.packages('ggplot2') # library(ggplot2) ggplot() + geom_point(aes(x = dataset$Level, y = dataset$Salary), color = 'red') + geom_line(aes(x = dataset$Level, y = predict(lin_reg, newdata = dataset)), color = 'blue') + ggtitle('Truth or Bluff (Linear Regression)') + xlab('Level') + ylab('Salary') # Visualising the Polynomial Regression results ggplot() + geom_point(aes(x = dataset$Level, y = dataset$Salary), color = 'red') + geom_line(aes(x = dataset$Level, y = predict(poly_reg, newdata = dataset)), color = 'blue') + ggtitle('Truth or Bluff (Polynomial Regression)') + xlab('Level') + ylab('Salary') # Predicting a new result with Linear Regression y_pred = predict(lin_reg, data.frame(Level = 6.5)) # Predicting a new result with Polynomial Regression y_pred = predict(poly_reg, data.frame(Level = 6.5, Level2 = 6.5^2, Level3 = 6.5^3, Level4 = 6.5^4)) |
Templates
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# Regression Template # Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd # Importing the dataset dataset = pd.read_csv('Position_Salaries.csv') X = dataset.iloc[:, 1:2].values y = dataset.iloc[:, 2].values # Splitting the dataset into the Training set and Test set """from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)""" # Feature Scaling """from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test) sc_y = StandardScaler() y_train = sc_y.fit_transform(y_train)""" # Fitting the Regression to the dataset # Create your regressor here # Predicting a new result y_pred = regressor.predict(6.5) # Visualizing the Regression results plt.scatter(X, y, color = 'red') plt.plot(X, regressor.predict(X), color = 'blue') plt.title('Truth or Bluff (Regression Model)') plt.xlabel('Position level') plt.ylabel('Salary') plt.show() # Visualizing the Regression results (for higher resolution and smoother curve) X_grid = np.arange(min(X), min(X), 0.1) X_grid = X_grid.reshape((len(X_grid), 1)) plt.scatter(X, y, color = 'red') plt.plot(X_grid, regressor.predict(X_grid), color = 'blue') plt.title('Truth or Bluff (Regression Model)') plt.xlabel('Position level') plt.ylabel('Salary') plt.show() |
R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# Regression Template # Importing the dataset dataset = read.csv('Position_Salaries.csv') dataset = dataset[2:3] # Splitting the dataset into the Training set and Test set # install.packages('caTools') # library(caTools) # set.seed(123) # split = sample.split(dataset$DependentVariable, SplitRatio = 0.8) # training_set = subset(dataset, split == TRUE) # test_set = subset(dataset, split == FALSE) # Feature Scaling # training_set = scale(training_set) # test_set = scale(test_set) # Fitting the Regression Model to the dataset # Create your regressor here # Predicting a new result y_pred = predict(regressor, data.frame(Level = 6.5)) # Visualising the Regression Model results # install.packages('ggplot2') # library(ggplot2) ggplot() + geom_point(aes(x = dataset$Level, y = dataset$Salary), color = 'red') + geom_line(aes(x = dataset$Level, y = predict(regressor, newdata = dataset)), color = 'blue') + ggtitle('Truth or Bluff (Regression Model)') + xlab('Level') + ylab('Salary') # Visualising the Regression Model results (for higher resolution and smoother curve) # install.packages('ggplot2') # library(ggplot2) x_grid = seq(min(dataset$Level), max(dataset$Level), 0.1) ggplot() + geom_point(aes(x = dataset$Level, y = dataset$Salary), color = 'red') + geom_line(aes(x = x_grid, y = predict(regressor, newdata = data.frame(Level = x_grid))), color = 'blue') + ggtitle('Truth or Bluff (Regression Model)') + xlab('Level') + ylab('Salary') |