Machine Learning A-Z: Part 2 – Regression (Simple Linear Regression)
Show current directory.
|
1 2 3 4 5 6 |
import os os.getcwd() (returns "a string representing the current working directory") os.chdir(path) ("change the current working directory to path") os.path.realpath(path) (returns "the canonical path of the specified filename, eliminating any symbolic links encountered in the path") os.path.dirname(path) (returns "the directory name of pathname path") |
Simple Linear Regression
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
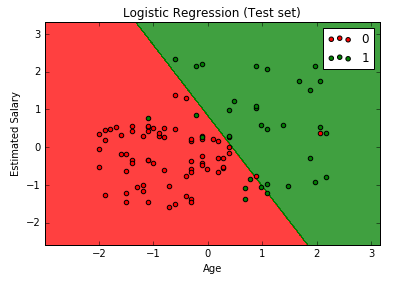
# Simple Linear Regression # Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd # Importing the dataset dataset = pd.read_csv('Salary_Data.csv') X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 1].values # Splitting the dataset into the Training set and Test set from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 1/3, random_state = 0) # Feature Scaling """from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test) sc_y = StandardScaler() y_train = sc_y.fit_transform(y_train)""" # Fitting Simple Linear Regression to the Training set from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, y_train) # Predicting the Test set results y_pred = regressor.predict(X_test) # Visualising the Training set results plt.scatter(X_train, y_train, color = 'red') plt.plot(X_train, regressor.predict(X_train), color = 'blue') plt.title('Salary vs Experience (Training set)') plt.xlabel('Years of Experience') plt.ylabel('Salary') plt.show() # Visualising the Test set results plt.scatter(X_test, y_test, color = 'red') plt.plot(X_train, regressor.predict(X_train), color = 'blue') plt.title('Salary vs Experience (Test set)') plt.xlabel('Years of Experience') plt.ylabel('Salary') plt.show() |

R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
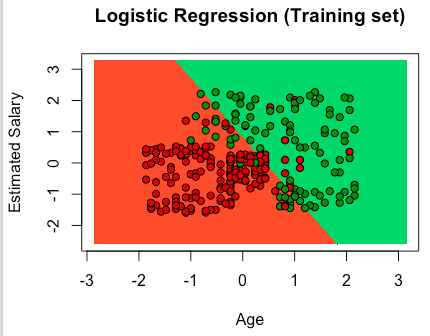
# Simple Linear Regression # Importing the dataset dataset = read.csv('Salary_Data.csv') # Splitting the dataset into the Training set and Test set # install.packages('caTools') library(caTools) set.seed(123) split = sample.split(dataset$Salary, SplitRatio = 2/3) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE) # Feature Scaling # training_set = scale(training_set) # test_set = scale(test_set) # Fitting Simple Linear Regression to the Training set regressor = lm(formula = Salary ~ YearsExperience, data = training_set) # Predicting the Test set results y_pred = predict(regressor, newdata = test_set) # Visualising the Training set results # install.packages('ggplot2') library(ggplot2) ggplot() + geom_point(aes(x = training_set$YearsExperience, y = training_set$Salary), colour = 'red') + geom_line(aes(x = training_set$YearsExperience, y = predict(regressor, newdata = training_set)), colour = 'blue') + ggtitle('Salary vs Experience (Training set)') + xlab('Years of experience') + ylab('Salary') # Visualising the Test set results # install.packages('ggplot2') # library(ggplot2) ggplot() + geom_point(aes(x = test_set$YearsExperience, y = test_set$Salary), colour = 'red') + geom_line(aes(x = training_set$YearsExperience, y = predict(regressor, newdata = training_set)), colour = 'blue') + ggtitle('Salary vs Experience (Test set)') + xlab('Years of experience') + ylab('Salary') |

Templates
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# Data Preprocessing Template # Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd # Importing the dataset dataset = pd.read_csv('Data.csv') X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 3].values # Splitting the dataset into the Training set and Test set from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) # Feature Scaling """from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test) sc_y = StandardScaler() y_train = sc_y.fit_transform(y_train)""" |
R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Data Preprocessing Template # Importing the dataset dataset = read.csv('Data.csv') # Splitting the dataset into the Training set and Test set # install.packages('caTools') library(caTools) set.seed(123) split = sample.split(dataset$DependentVariable, SplitRatio = 0.8) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE) # Feature Scaling # training_set = scale(training_set) # test_set = scale(test_set) |