– a way of programming agents by reward and punishment without needing to specify how the task is to be achieved.
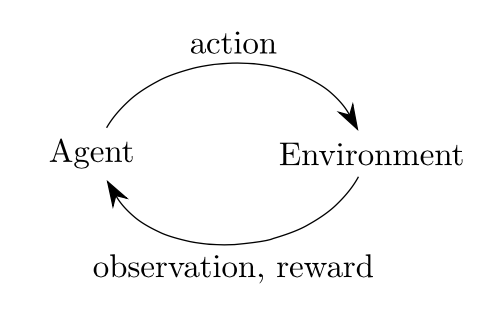
– The basic RL problem includes states (s), actions (a) and rewards (r). The typical formulation is as follows:
1. Observe state
2. Decide on an action
3. Perform action
4. Observe new state
5. Observe reward
6. Learn from experience
7. Repeat
– an area of machine learning inspired by behaviorist psychology
– concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward.
In machine learning, the environment is typically formulated as a Markov decision process (MDP)
The difference between the classical techniques and RL
– RL do not need knowledge about the MDP and they target large MDPs where exact methods become infeasible.
– In RL, correct input/output pairs are never presented, nor sub-optimal actions explicitly corrected.
– Further, there is a focus on on-line performance, which involves finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).
– provide a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker.
– useful for studying a wide range of optimization problems solved via dynamic programming and reinforcement learning.
The environment’s step function returns four values:
observation (object):
– an environment-specific object representing your observation of the environment.
e.g.
– pixel data from a camera
– joint angles and joint velocities of a robot
– the board state in a board game.
reward (float):
– amount of reward achieved by the previous action.
– The scale varies between environments, but the goal is always to increase your total reward.
done (boolean):
– whether it’s time to reset the environment again.
– Most (but not all) tasks are divided up into well-defined episodes, and done being True indicates the episode has terminated.
e.g.
– perhaps the pole tipped too far, or you lost your last life.
info (dict):
– diagnostic information useful for debugging.
– It can sometimes be useful for learning
e.g. it might contain the raw probabilities behind the environment’s last state change.
– However, official evaluations of your agent are not allowed to use this for learning.
=> agent-environment loop
Each timestep,
– the agent chooses an action
– the environment returns an observation and a reward.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import gym
env=gym.make('CartPole-v0')
fori_episode inrange(20):
observation=env.reset()
fortinrange(100):
env.render()
print(observation)
action=env.action_space.sample()
observation,reward,done,info=env.step(action)
ifdone:
print("Episode finished after {} timesteps".format(t+1))
break
observation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
[0.01936616-0.026672230.04207677-0.03210077]
[0.018832720.167821860.04143476-0.31121675]
[0.02218916-0.027865170.03521042-0.00575982]
[0.02163185-0.223473930.035095230.29782119]
[0.01716237-0.419078130.041051650.60136269]
[0.00878081-0.614749570.05307890.90668836]
[-0.00351418-0.420384890.071212670.63114982]
[-0.01192188-0.226325020.083835670.36171663]
[-0.01644838-0.032488530.091070.0966019]
[-0.01709815-0.228789730.093002040.41657106]
[-0.02167394-0.035100390.101333460.15459582]
[-0.02237595-0.231516250.104425380.47744932]
[-0.02700628-0.038011710.113974360.21941893]
[-0.02776651-0.234562740.118362740.5457686]
[-0.03245777-0.43113150.129278110.87327618]
[-0.0410804-0.627751870.146743641.2036476]
[-0.05363543-0.824433910.170816591.53848784]
[-0.07012411-0.631729240.201586341.3036139]
Episode finished after18timesteps
Spaces
1
2
3
4
5
6
import gym
env=gym.make('CartPole-v0')
print(env.action_space)
#> Discrete(2)
print(env.observation_space)
#> Box(4,)
The Discrete space
– allows a fixed range of non-negative numbers,
– in this case, valid actions are either 0 or 1.
The Box space
– represents an n-dimensional box,
– valid observations will be an array of 4 numbers.
1
2
3
4
print(env.observation_space.high)
#> array([ 2.4 , inf, 0.20943951, inf])
print(env.observation_space.low)
#> array([-2.4 , -inf, -0.20943951, -inf])
Box and Discrete: the most common Spaces.
1
2
3
4
5
from gym import spaces
space=spaces.Discrete(8)# Set with 8 elements {0, 1, 2, ..., 7}
EnvSpec(environment ID)
– define parameters for a particular task, including the number of trials to run and the maximum number of steps.
e.g.
EnvSpec(Hopper-v1)
– defines an environment where the goal is to get a 2D simulated robot to hop;
EnvSpec(Go9x9-v0)
– defines a Go game on a 9×9 board.
Recording and uploading results
Use Monitor() to export your algorithm’s performance as a JSON file:
2 basic concepts:
1) the environment: the outside world;
2) the agent: the algorithm you are writing.
– The agent sends actions to the environment, and the environment replies with observations and rewards (a score).
– a non-profit artificial intelligence (AI) research company
– one of founders is Elon Musk.
– aims to carefully promote and develop friendly AI in such a way as to benefit humanity as a whole.
– The founders are motivated in part by concerns about existential risk from artificial general intelligence.
– a toolkit for developing and comparing reinforcement learning (RL) algorithms.
– consists of a growing suite of environments (from simulated robots to Atari games), and a site for comparing and reproducing results.
– compatible with algorithms written in any framework, such as Tensorflow and Theano.
– As of May 2017, “OpenAI Gym” can only be used through Python, but more languages are coming soon.
– a software platform for measuring and training an AI’s general intelligence across the world’s supply of games, websites and other applications.
– allows an AI agent to use a computer like a human does: by looking at screen pixels and operating a virtual keyboard and mouse.