OpenAI Gym Tutorial
From a tutorial:
https://gym.openai.com/docs
Observations
The environment’s step function returns four values:
observation (object):
– an environment-specific object representing your observation of the environment.
e.g.
– pixel data from a camera
– joint angles and joint velocities of a robot
– the board state in a board game.
reward (float):
– amount of reward achieved by the previous action.
– The scale varies between environments, but the goal is always to increase your total reward.
done (boolean):
– whether it’s time to reset the environment again.
– Most (but not all) tasks are divided up into well-defined episodes, and done being True indicates the episode has terminated.
e.g.
– perhaps the pole tipped too far, or you lost your last life.
info (dict):
– diagnostic information useful for debugging.
– It can sometimes be useful for learning
e.g. it might contain the raw probabilities behind the environment’s last state change.
– However, official evaluations of your agent are not allowed to use this for learning.
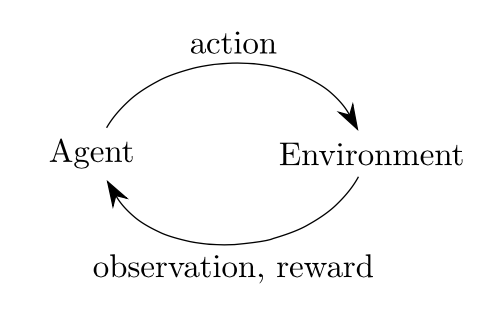
=> agent-environment loop
Each timestep,
– the agent chooses an action
– the environment returns an observation and a reward.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import gym env = gym.make('CartPole-v0') for i_episode in range(20): observation = env.reset() for t in range(100): env.render() print(observation) action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("Episode finished after {} timesteps".format(t+1)) break |
observation
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[ 0.01936616 -0.02667223 0.04207677 -0.03210077] [ 0.01883272 0.16782186 0.04143476 -0.31121675] [ 0.02218916 -0.02786517 0.03521042 -0.00575982] [ 0.02163185 -0.22347393 0.03509523 0.29782119] [ 0.01716237 -0.41907813 0.04105165 0.60136269] [ 0.00878081 -0.61474957 0.0530789 0.90668836] [-0.00351418 -0.42038489 0.07121267 0.63114982] [-0.01192188 -0.22632502 0.08383567 0.36171663] [-0.01644838 -0.03248853 0.09107 0.0966019 ] [-0.01709815 -0.22878973 0.09300204 0.41657106] [-0.02167394 -0.03510039 0.10133346 0.15459582] [-0.02237595 -0.23151625 0.10442538 0.47744932] [-0.02700628 -0.03801171 0.11397436 0.21941893] [-0.02776651 -0.23456274 0.11836274 0.5457686 ] [-0.03245777 -0.4311315 0.12927811 0.87327618] [-0.0410804 -0.62775187 0.14674364 1.2036476 ] [-0.05363543 -0.82443391 0.17081659 1.53848784] [-0.07012411 -0.63172924 0.20158634 1.3036139 ] Episode finished after 18 timesteps |
Spaces
|
1 2 3 4 5 6 |
import gym env = gym.make('CartPole-v0') print(env.action_space) #> Discrete(2) print(env.observation_space) #> Box(4,) |
The Discrete space
– allows a fixed range of non-negative numbers,
– in this case, valid actions are either 0 or 1.
The Box space
– represents an n-dimensional box,
– valid observations will be an array of 4 numbers.
|
1 2 3 4 |
print(env.observation_space.high) #> array([ 2.4 , inf, 0.20943951, inf]) print(env.observation_space.low) #> array([-2.4 , -inf, -0.20943951, -inf]) |
Box and Discrete: the most common Spaces.
|
1 2 3 4 5 |
from gym import spaces space = spaces.Discrete(8) # Set with 8 elements {0, 1, 2, ..., 7} x = space.sample() # 4. assert space.contains(x) # space contains 4. assert space.n == 8 # space has 8 elements. |
Environments
|
1 2 3 |
from gym import envs print(envs.registry.all()) #> [EnvSpec(DoubleDunk-v0), EnvSpec(InvertedDoublePendulum-v0), EnvSpec(BeamRider-v0), EnvSpec(Phoenix-ram-v0), EnvSpec(Asterix-v0), EnvSpec(TimePilot-v0), EnvSpec(Alien-v0), EnvSpec(Robotank-ram-v0), EnvSpec(CartPole-v0), EnvSpec(Berzerk-v0), EnvSpec(Berzerk-ram-v0), EnvSpec(Gopher-ram-v0), ... |
EnvSpec(environment ID)
– define parameters for a particular task, including the number of trials to run and the maximum number of steps.
e.g.
EnvSpec(Hopper-v1)
– defines an environment where the goal is to get a 2D simulated robot to hop;
EnvSpec(Go9x9-v0)
– defines a Go game on a 9×9 board.
Recording and uploading results
Use Monitor() to export your algorithm’s performance as a JSON file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import gym from gym import wrappers env = gym.make('CartPole-v0') env = wrappers.Monitor(env, '/tmp/cartpole-experiment-1') for i_episode in range(20): observation = env.reset() for t in range(100): env.render() action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("Episode finished after {} timesteps".format(t+1)) break |
To upload your results to OpenAI Gym:
|
1 2 |
import gym gym.upload('/tmp/cartpole-experiment-1', api_key='YOUR_API_KEY') |